Docker 在数据处理与存储支持服务中的应用
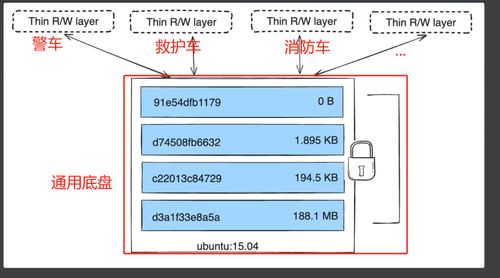
随着云计算和微服务架构的普及,Docker 已成为现代应用开发和部署的核心技术之一。在数据处理与存储支持服务中,Docker 提供了高效、可扩展且一致的解决方案。通过容器化数据工具、存储系统和相关服务,Docker 使得数据处理流程更加灵活和可靠。
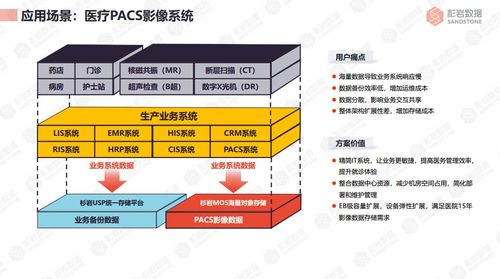
Docker 支持数据处理的容器化部署。用户可以将数据采集、清洗、分析等工具(如 Apache Spark、Pandas 或 Kafka)打包成容器镜像。这不仅简化了环境配置,还确保了在不同环境中运行的应用程序具有相同的行为。例如,数据科学家可以在本地开发环境中运行容器化的 Jupyter Notebook,然后无缝部署到生产环境,避免因环境差异导致的问题。
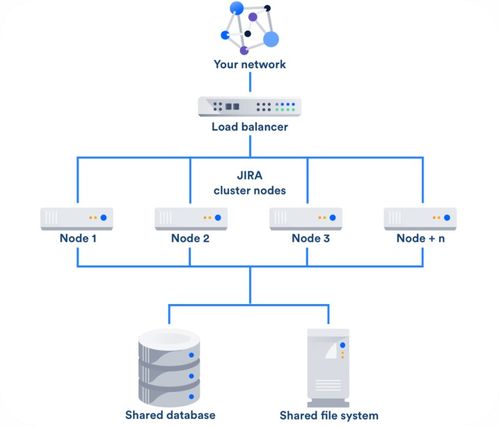
在存储方面,Docker 通过卷(volumes)和绑定挂载(bind mounts)提供了数据持久化支持。卷是 Docker 管理的存储机制,适用于保存数据库文件、日志或其他重要数据,即使在容器删除后数据仍然保留。例如,运行 PostgreSQL 数据库容器时,可以创建一个卷来存储数据库文件,确保数据的持久性和可恢复性。绑定挂载则允许将宿主机的目录挂载到容器中,便于实时数据共享和备份。
Docker Compose 和 Kubernetes 等编排工具进一步增强了数据处理与存储服务的可管理性。通过 Docker Compose,用户可以定义多容器应用,如一个包含数据处理服务和数据库的堆栈,实现一键部署。Kubernetes 则支持大规模容器编排,自动扩展数据处理任务,并集成持久卷(Persistent Volumes)以提供高可用存储。
使用 Docker 时也需注意一些挑战,例如数据安全性和性能优化。建议采用加密卷、访问控制和定期备份策略来保护敏感数据。监控容器资源使用情况,避免存储 I/O 瓶颈,确保数据处理任务高效运行。
Docker 在数据处理和存储支持服务中发挥了关键作用,通过容器化、持久化存储和编排工具,它简化了复杂数据流程的管理,提升了可移植性和效率。随着技术的演进,Docker 将继续推动数据驱动应用的创新。
如若转载,请注明出处:http://www.668a2.com/product/9.html
更新时间:2026-06-19 17:01:52