基于Flink构建全场景实时数仓 数据处理和存储支持服务
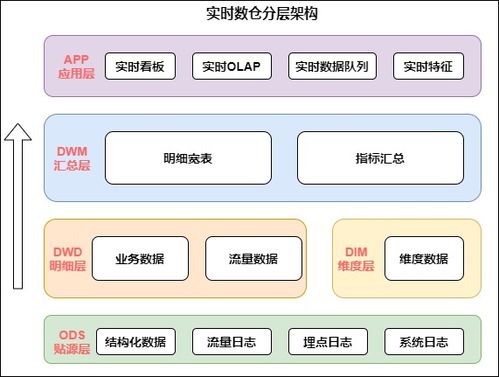
随着大数据技术的快速发展,企业对数据实时性的需求日益增长。Flink作为一款开源的流处理框架,凭借其高吞吐、低延迟和精确一次处理语义等特性,成为构建全场景实时数仓的理想选择。本文将探讨如何基于Flink实现全场景实时数仓的数据处理和存储支持服务,涵盖核心架构、数据处理流程、存储方案以及实际应用场景。
一、Flink在全场景实时数仓中的核心作用
Flink不仅支持流式数据处理,还能通过其状态管理和事件时间处理机制,确保数据在复杂场景下的准确性和一致性。在全场景实时数仓中,Flink负责从多源(如Kafka、数据库日志、IoT设备)实时摄入数据,进行清洗、转换、聚合和关联分析,最终输出到存储层或下游应用。其优势包括:
- 低延迟处理:毫秒级响应,满足实时监控和决策需求。
- 容错性:通过检查点机制保障数据不丢失。
- 灵活性:支持SQL、DataStream API等多种编程模式,适配不同业务场景。
二、数据处理流程与关键技术
构建全场景实时数仓时,数据处理流程通常包括数据摄入、实时计算和数据输出三个阶段。Flink在其中扮演核心角色:
- 数据摄入:通过Flink Connector连接Kafka、MySQL等数据源,实现增量数据同步。例如,使用CDC(Change Data Capture)技术捕获数据库变更,并实时流入Flink作业。
- 实时计算:Flink作业对数据进行ETL操作,如过滤无效数据、字段映射、窗口聚合(如滚动窗口、滑动窗口)和复杂事件处理(CEP)。通过状态后端(如RocksDB)管理中间状态,支持大规模数据持久化。
- 数据输出:处理结果可实时写入存储系统(如HDFS、HBase、Elasticsearch)或消息队列(如Kafka),供可视化工具或业务系统调用。
三、存储支持服务的设计
全场景实时数仓的存储层需满足高可用、可扩展和低延迟查询需求。Flink与多种存储系统集成,提供灵活支持:
- OLAP存储:如ClickHouse或Doris,用于快速多维分析,Flink可直接输出聚合结果到这些系统。
- NoSQL数据库:如HBase或Cassandra,存储明细数据,支持随机读写。
- 数据湖:如Iceberg或Hudi,结合Flink实现流批一体,保障数据一致性和事务支持。
可通过Flink的Table API将数据统一抽象为表结构,简化查询和治理。
四、全场景应用实践
在实际场景中,基于Flink的实时数仓已广泛应用于电商、金融和物联网领域:
- 电商实时推荐:实时分析用户行为数据,通过Flink计算兴趣模型,并更新推荐结果。
- 金融风控:监控交易流水,使用Flink CEP检测异常模式,及时触发告警。
- IoT设备监控:处理传感器数据流,进行实时聚合和预测性维护。
这些案例展示了Flink如何助力企业实现数据驱动决策,提升业务敏捷性。
五、总结与展望
基于Flink构建全场景实时数仓,不仅解决了传统批处理延迟高的问题,还通过流批一体架构降低了运维成本。随着Flink与云原生、AI技术的深度融合,实时数仓将更智能、高效。企业应注重数据治理和架构优化,以充分发挥Flink的潜力,构建稳定可靠的实时数据处理生态系统。
如若转载,请注明出处:http://www.668a2.com/product/17.html
更新时间:2026-06-19 21:26:25